
Introducing Voxtral: Mistral’s Open Source AI Audio Family
What is Voxtral and why it matters
Voxtral marks a significant milestone for Mistral, a French AI startup known for its commitment to open-source innovation. This new family of AI audio models aims to democratize speech recognition and understanding, offering developers and businesses an alternative to proprietary solutions from giants like OpenAI and Google. Unlike closed systems that lock users into high costs or limited customization, Voxtral is designed to be flexible, transparent, and cost-effective.
What makes Voxtral stand out is its open-weight architecture, meaning anyone can access, modify, or deploy these models without restrictions. This openness fosters a collaborative environment where improvements can be shared openly, potentially accelerating progress in speech AI technology. In addition, Voxtral’s capability to deploy “truly usable speech intelligence” means it isn’t just about transcribing speech but understanding context—answering questions about the content, summarizing lengthy recordings, or executing voice commands in real time.
The importance of this development extends beyond startups; enterprises seeking reliable yet affordable transcription solutions now have a credible open-source option that balances performance with price. As speech becomes increasingly central in digital interfaces—think virtual assistants, customer service bots, and accessibility tools—Voxtral positions itself as an accessible solution that puts control back into the hands of developers.
The journey of Mistral in AI development
Mistral‘s journey has been marked by a clear focus on pushing the boundaries of open-source AI. Founded with the vision of creating transparent alternatives to dominant corporate models, Mistral gained rapid attention within the tech community for its innovative approach. Its earlier efforts included developing reasoning models like Magistral—aimed at solving complex problems through step-by-step logic—and advocating for more open access in AI research.
The company’s strategy revolves around challenging the status quo set by big players such as OpenAI and Google. While these corporations typically operate under walled gardens with costly API services and proprietary weights, Mistral emphasizes community-driven development and lower-cost deployment options. Their recent fundraising talks for up to $1 billion highlight how much confidence investors have in their approach.
By releasing Voxtral as an open-source family specifically tailored for audio tasks—including transcription, translation, summarization, and voice command execution—Mistral continues its mission to make advanced speech AI accessible while maintaining control over deployment environments. Their model sizes range from lightweight variants suitable for edge devices to larger versions intended for enterprise-scale applications—underscoring their versatility across different use cases.
Key features that set Voxtral apart
One glance at Voxtral reveals several features making it a standout:
Open source architecture: Developers can freely access weights via platforms like Hugging Face (Hugging Face) and customize models according to their needs.
Multilingual support: It supports major languages including English, Spanish, French, Portuguese, Hindi, German, Dutch—and Italian—broadening usability globally.
Model variants: The two main flavors are:
- Voxtral Small with 24 billion parameters suited for production-level tasks,
- Voxtral Mini with 3 billion parameters optimized for local or edge deployment.
Speech understanding capabilities: Beyond simple transcription (up to 30 minutes per audio file), Voxtral can answer questions about spoken content or generate summaries thanks to its underlying LLM backbone based on Mistral Small 3.1.
API flexibility & pricing: Starting at just $0.001 per minute of audio processed (pricing details), it’s significantly cheaper than comparable offerings from other providers.
Fast API version: For transcription-only purposes needing quick turnarounds at minimal cost (less than half what OpenAI Whisper charges), Voxtral Mini Transcribe promises faster processing times paired with affordability.
These features collectively make Voxtral not only technically compelling but also economically attractive—a combination that’s rare among high-performance speech recognition systems.
Cost-Effective Transcription with Voxtral Compared to Giants
Voxtral’s API transcription pricing advantages
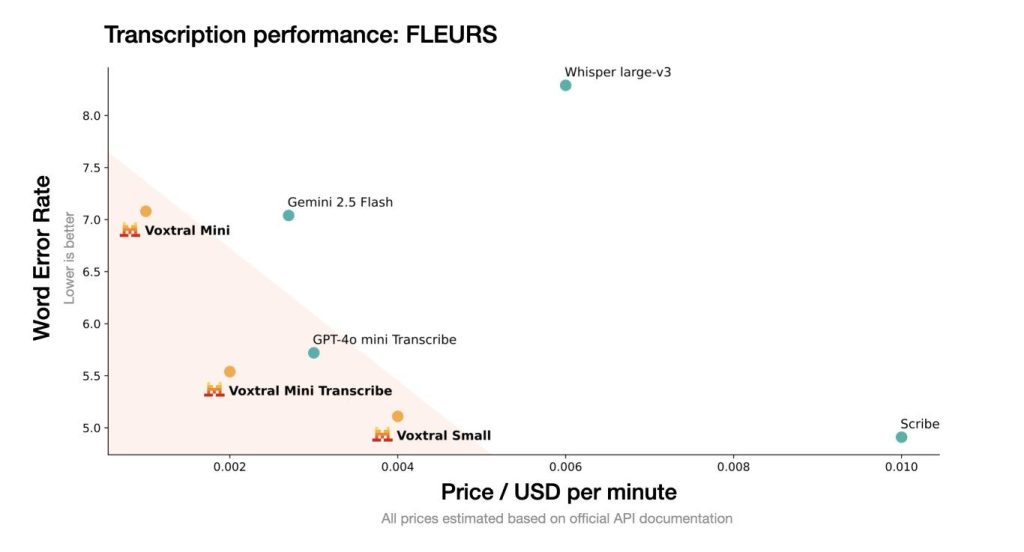
When it comes to cost efficiency in transcribing large volumes of speech data—or even small projects—the numbers tell a compelling story. Traditional providers like OpenAI or Google tend to charge premium rates:
| Provider | Price per Minute | Notable Features |
|---|---|---|
| OpenAI Whisper | ~$0.006–$0.008 | High accuracy but expensive |
| Google Speech-to-Text | ~$0.006–$0.009 | Extensive language support |
| Voxtral Mini Transcribe | $0.001 | Fastest & cheapest; optimized solely for transcription |
This table highlights how Voxelral’s API offers roughly less than half the price of those major services while still delivering competitive quality—even outperforming some in speed due to tailored optimizations.
Furthermore, since the API starts at just $0.001 per minute (see here), small startups or individual developers working on tight budgets can process thousands of hours without breaking the bank—a stark contrast against traditional cloud APIs that quickly rack up costs.
How Voxtral stacks up against OpenAI and Google
While exact performance metrics depend on specific use cases (like audio quality or language complexity), initial tests indicate that Voxtral provides comparable accuracy levels while being more budget-friendly:
- It performs well on multilingual datasets where proprietary APIs may struggle.
- Its ability to understand context allows better handling of homophones or ambiguous phrases.
- Edge deployment options mean reduced latency and operational costs outside cloud environments.
In practical terms: companies needing large-scale transcriptions often face trade-offs between quality and expense when choosing between closed systems from OpenAI or Google versus open alternatives like Voxtral—which now offers both affordability and transparency.
Real-world use cases benefiting from cheaper transcriptions
The economic advantages translate directly into broader application possibilities:
- Media companies can transcribe interviews or podcasts rapidly without overspending.
- Customer service centers deploying voice bots benefit from real-time responses at low cost.
- Accessibility initiatives, such as generating subtitles for videos across multiple languages affordably.
- Research projects involving extensive audio data analysis become feasible without prohibitive licensing fees.
In each case, employing voxtra models means organizations can scale their projects efficiently while maintaining control over data privacy—an increasingly critical factor in today’s digital landscape.
Frequently asked questions on Voxtral
What is Voxtral and how does it compare to other AI audio models?
It is Mistral’s open-source family of AI audio models designed for speech recognition, transcription, and understanding. Unlike proprietary solutions from OpenAI or Google, Voxtral offers transparency and customization options. It supports multiple languages and provides different model variants tailored for various deployment needs. When compared to other models, Voxtral stands out for its cost-effectiveness—offering API transcription at a fraction of the price—while still maintaining competitive accuracy.
Why is Voxtral considered more affordable than OpenAI or Google speech APIs?
The main reason it is cheaper is because it’s open source and designed for lower-cost deployment. Its API pricing starts at just $0.001 per minute of audio, which is significantly less than OpenAI Whisper (~$0.006–$0.008) or Google Speech-to-Text (~$0.006–$0.009). This means startups, researchers, and developers can process large volumes of speech data without hefty costs, making Voxtral a practical choice for budget-conscious projects.
Can Voxtral handle multilingual transcription and understanding?
Absolutely! it supports major languages including English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian. Its multilingual capabilities make it suitable for global applications like subtitles generation across different regions or international customer support automation. Plus, its ability to understand context allows it not just to transcribe but also to answer questions about spoken content or generate summaries.
What are some common use cases for Voxtral’s low-cost transcriptions?
Many organizations are already benefiting from its affordability: media companies transcribing interviews quickly; customer service centers deploying voice bots affordably; accessibility tools creating subtitles in multiple languages; and research teams analyzing extensive audio datasets—all leveraging the cost savings without sacrificing performance.