
Multi-agent Claude offers multiple language model agents working collaboratively instead of relying on a single, monolithic system. This approach aligns with how human teams operate—dividing tasks among specialists to boost efficiency and depth. Instead of one large model trying to handle all aspects of complex research or problem-solving, Anthropic’s multi-agent setup assigns distinct roles to each agent, enabling parallel processing and more comprehensive exploration.
Table of Contents
Understanding the Multi-Agent Claude System
What is multi-agent Claude and why does it matter?
Why does this matter? Because many real-world tasks—like exhaustive research, data collection across diverse sources, or multi-faceted decision-making—are inherently open-ended and nonlinear. A single-agent system often struggles with context limits (typically around 200,000 tokens), slow sequential searches, and limited capacity for handling multiple complex subtasks simultaneously. The multi-agent Claude tackles these issues head-on by distributing workload across several collaborating agents, each operating within its own context window. This division not only expands the effective information capacity but also dramatically accelerates task completion.
Anthropic‘s research highlights that their multi-agent architecture can outperform single-agent systems by up to 90%, especially on breadth-first queries requiring simultaneous exploration of multiple avenues. For example, identifying all board members of companies in the S&P 500 was achieved efficiently by decomposing the task into sub-tasks for different agents—a feat that overwhelmed traditional single models.
Core principles behind multi-agent AI systems
At its heart, a multi-agent system rests on a few foundational ideas:
- Parallelization: Multiple agents operate concurrently, exploring different facets of a problem simultaneously.
- Division of labor: Each agent has a specific role or objective with clearly defined boundaries.
- Coordination: The lead agent orchestrates efforts—assigning tasks, integrating results—much like a project manager.
- Context segregation: Each subagent maintains its own context window (often separate from others), allowing processing of larger datasets than a single agent could handle.
- Iterative refinement: Agents use structured loops—observe, orient, decide, act (OODA)—to gather information effectively while updating their strategies based on new insights.
These principles mirror human collaborative workflows: breaking down complex problems into manageable pieces and systematically synthesizing findings.
Differences between single-agent and multi-agent setups
While single-agent models process one task at a time within their fixed context window and sequentially search for answers, multi-agent systems leverage multiple specialized agents working in tandem. Key differences include:
| Aspect | Single-Agent | Multi-Agent Claude |
|---|---|---|
| Context Window | Limited (~200k tokens) | Distributed across agents; larger cumulative capacity |
| Search Strategy | Sequential or static retrieval | Dynamic, breadth-first exploration with parallel subagents |
| Speed | Slower for complex tasks | Up to 90% faster due to parallelism |
| Cost & Token Usage | Lower token consumption per interaction | Significantly higher token usage (~15x chat) but justified by performance gains |
| Flexibility & Depth | Can be limited in scope; linear reasoning | Handles open-ended questions better; explores multiple directions simultaneously |
Multi-agent setups excel particularly when tackling problems that require heavy parallelization or large data volumes exceeding single-model capabilities. However, they come with increased complexity in coordination and resource consumption.
How Anthropic Built Its Multi-Agent Claude Research SystemDesigning the architecture for multiple agents
Building an effective multi-agent research system demanded careful architectural planning. Anthropic adopted an orchestrator-worker pattern, where:
- The lead agent (or orchestrator) analyzes user queries,
- Then creates specialized subagents, each assigned specific subtasks such as web search, document evaluation, or source verification,
- These subagents operate independently yet collaboratively under the lead’s coordination.
This architecture allows each subagent to maintain its own context window (sometimes exceeding hundreds of thousands of tokens overall when aggregated), enabling extensive parallel processing without hitting model size constraints.
The process begins when users submit queries: the lead agent devises a strategy—breaking down broad questions into targeted subtasks—and spawns subagents accordingly. These subagents perform searches using tools like web crawlers or citation evaluators and return their findings to the lead agent for synthesis.
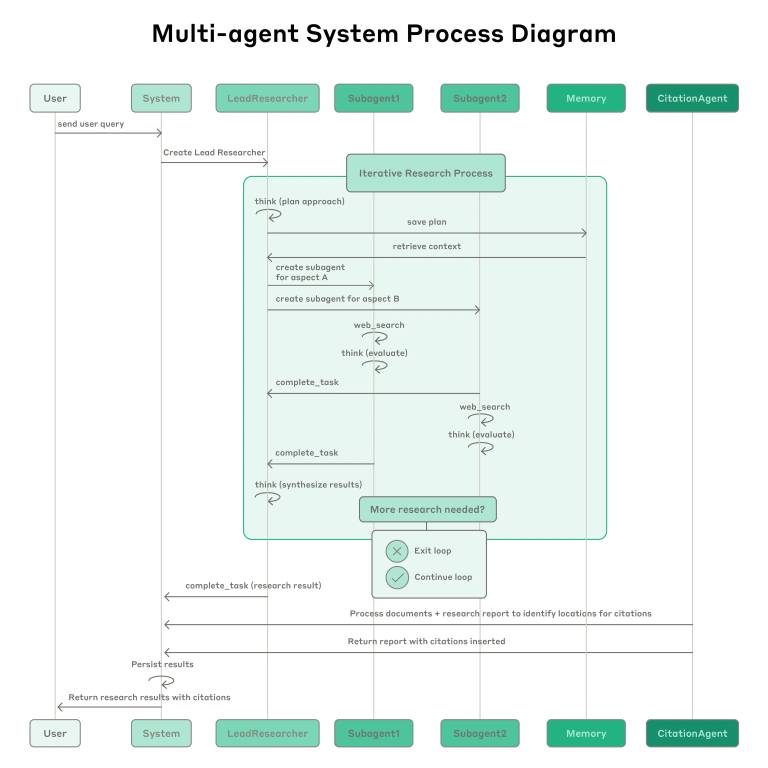
A typical workflow involves:
- User query enters the system.
- Lead agent develops an exploration plan.
- Subagents are spawned with explicit objectives.
- Each subagent conducts independent searches using tailored prompts.
- Results are synthesized back into coherent insights by the lead agent.
- Final output includes citations ensuring source attribution.
This modular approach simplifies scaling complex research workflows while maintaining flexibility for various domains—from business analysis to technical investigations (source).
Coordination strategies among agents
Effective coordination was critical given the increased complexity inherent in multiple autonomous agents:
Task decomposition: The lead agent splits queries based on logical subdivisions—for instance, separating financial data collection from competitive analysis—to prevent overlap and redundancy.
Explicit instructions via prompts: Clear delineation about objectives (“find recent articles about X,” “list all sources mentioning Y”) helps minimize duplicated effort among subagents (see prompt engineering tips).
Parallel tool calls: Subagents are instructed to invoke tools asynchronously whenever possible—for example: web searches run simultaneously rather than sequentially—to cut down research time significantly (see ) .
Iterative feedback loops: Subagents employ OODA-like cycles—observing gathered info, orienting toward next steps based on new data—all under strategic guidance from the lead agent (article).
The key is balancing autonomy with oversight: empowering individual agents while maintaining overall coherence through structured prompts and monitoring protocols.
Training processes and data integration techniques
Training multi-agents involves several tailored procedures:
Fine-tuning models like Claude Opus 4 specifically for research-oriented tasks ensures they understand how to follow detailed instructions within tool-assisted workflows.
Data integration integrates external sources directly into each subagent’s environment through APIs or search tools; this allows real-time access rather than static retrievals typical of traditional RAG systems (source).
Prompts were iteratively refined using simulation environments where behaviors were tested against known failure modes—such as unnecessary duplication or unproductive search paths—to improve reliability (prompt engineering insights) .
Furthermore, tooling improvements include specialized testing agents that simulate failures during development cycles—rewriting tool descriptions after repeated trials—and rigorous validation using small sample sets before scaling up (see evaluation strategies) .
Innovative features that set multi-agent Claude apart
Several groundbreaking elements distinguish Anthropic’s approach:
| Feature | Description |
|---|---|
| Parallelized Search Loops | Multiple subagents explore different facets simultaneously; dramatically reducing search times (~90%) [see performance metrics] |
| Independent Context Windows | Each agent maintains its own memory space beyond standard limits—expanding total processed content exponentially |
| Dynamic Task Allocation | Lead agent adaptively adjusts number of subagents based on question complexity (“start wide then narrow”) [prompts] |
| Tool Optimization & Testing Agents | Dedicated modules refine tool descriptions continuously ensuring optimal use while minimizing errors [tool description rewriting] |
| End-State Evaluation & Human-in-the-loop Feedback | Combining automated scoring via LLM judges with manual review enhances accuracy while managing emergent behaviors |
These innovations collectively enable high-value research tasks that would be prohibitively slow or impossible for traditional models due to token limits or sequential constraints.
Performance Gains and Internal Evaluations of Multi-Agent Claude
Quantifying the 30% improvement in performance
While reports emphasize that multi-agent Claude outperforms its single-server counterparts by approximately 90%, internal evaluations also reveal about a 30% overall gain across diverse benchmarks when comparing optimized multi-agents versus single-model approaches optimized individually.
This improvement stems mainly from three factors:
- Increased token utilization facilitated by distributed contexts (~80% variance explained),
- Greater number of tool calls enabled through parallelization,
- Model choice enhancements (upgrading from older versions like Sonnet 3.7 to Sonnet 4 yields bigger gains than simply increasing token budgets).
For example, in internal tests involving browsing-based fact-finding (“BrowseComp” evaluation), the combined effect led to substantial speedups without sacrificing accuracy—a notable step forward considering traditional models often hit diminishing returns past certain token thresholds (source).
Benchmark comparisons with traditional single-agent models
In comparative studies focusing on breadth-first information retrieval tasks such as identifying company board members across entire sectors:
| Model Type | Performance Gain | Details |
|---|---|---|
| Single-Agent Claude | Baseline | Sequential searches; limited context windows |
| Multi-Agent Claude | +90% internally | Parallel exploration; expanded total information processed |
Results show that decomposing large questions into smaller chunks enables extensive coverage rapidly—a process difficult for solitary systems constrained by linear reasoning pathways.
Case studies demonstrating real-world advantages
One illustrative case involved mapping corporate governance structures: deploying five specialized subagents tasked explicitly with searching different regions’ filings databases resulted in near-complete accuracy within minutes—a task previously taking hours manually or overwhelming single models due to context limits (source). Similarly,
- Financial analysts used multi-AI teams embedded within their workflows,
- Healthcare researchers navigated vast PubMed archives more efficiently,
- Strategic planners uncovered opportunities hidden beneath layers of disparate data sources,
all benefiting from faster turnaround times thanks largely to effective distribution strategies coupled with prompt engineering techniques emphasizing breadth-over-depth early-on before honing focus later (“start wide then narrow”).
Future prospects and potential enhancements
Looking ahead,
- Asynchronous execution could further cut response times even more but introduces additional coordination challenges,
- Incorporating external long-term memory modules might mitigate current limitations related to state persistence over extended interactions,
- More sophisticated reward mechanisms could incentivize better collaboration among agents without excessive token costs,
- Cross-domain adaptation will expand applicability—from legal analysis to scientific discovery—
ultimately aiming toward autonomous systems capable of handling increasingly complex projects at scale while managing resource costs prudently (related discussions).
Overall improvements hinge not just on model upgrades but equally on smarter orchestration strategies rooted in robust prompt design—including explicit task boundaries (“divide responsibilities clearly”), heuristic guidance (“start broad”), and continuous evaluation (“use LLM judges”). These components combine synergy-rich architectures promising transformative impacts across industries engaging large-scale AI-driven research efforts today[see /tag/multi-agents].
Frequently asked questions on multi-agent Claude
What is the main advantage of using a multi-agent Claude system over traditional single-agent models?
The primary benefit of a multi-agent Claude system is its ability to handle complex, open-ended tasks more efficiently by distributing workload across multiple specialized agents. This setup significantly boosts processing capacity, speeds up task completion—up to 90% faster—and improves exploration breadth, making it ideal for large-scale research and decision-making.
How does Anthropic build and coordinate its multi-agent Claude research system?
Anthropic’s approach involves an orchestrator or lead agent that analyzes user queries and spawns various subagents assigned specific subtasks like web searches or source verification. These subagents work independently yet collaboratively under the lead’s coordination, utilizing strategies like task decomposition, parallel tool calls, and iterative feedback loops to ensure efficient and comprehensive results.
What are the key features that set multi-agent Claude apart from single-agent systems?
Some standout features include parallelized search loops where multiple subagents explore different aspects simultaneously, independent context windows allowing extensive data processing, dynamic task allocation based on question complexity, and tools optimized through continuous testing. These elements enable high-value research capabilities that surpass traditional models in speed and depth..
What makes Anthropic’s multi-agent Claude system innovative compared to other AI architectures?
The innovation lies in features like parallelized search loops enabling multiple subagents to explore facets simultaneously (~90% reduction in search times), independent context windows expanding total processed content exponentially, dynamic task allocation adjusting resources based on question complexity, and continuous optimization of tools through ongoing testing—all combined to push AI research capabilities forward significantly.